

AOF是Redis另外一种持久化方式,是通过保存Redis服务器所执行的写命令来记录数据库状态的
比如:
set msg "hello"
对于上面执行的写命令来说,AOF文件内容为:
2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
3\r\n$3\r\nSET\r\n$3\r\nmsg\r\n$5\r\nhello\r\n
AOF持久化功能处于打开状态时,服务器在执行完之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf 缓冲区的末尾
struct redisServer {
// aof缓冲区
sds aof_buf;
}
/* AOF postponed flush: Try at every cron cycle if the slow fsync
* completed. */
if (server.aof_flush_postponed_start) flushAppendOnlyFile(0);
/* AOF write errors: in this case we have a buffer to flush as well and
* clear the AOF error in case of success to make the DB writable again,
* however to try every second is enough in case of 'hz' is set to
* an higher frequency. */
run_with_period(1000) {
if (server.aof_last_write_status == REDIS_ERR)
flushAppendOnlyFile(0);
}
flushAppendOnlyFile的函数行为由服务器所配置appendfsync选项的值来决定
always,将aof_buf缓冲区的所有内容写入并同步到AOF文件中;
everysec,将aof_buf缓冲区的所有内容写入到AOF文件,如果上次同步的时候距离现在一秒钟,那么再次对AOF文件进行同步,这个操作由一个线程掌控;
no,将aof_buf缓冲区的所有内容写到AOF文件中,但并不对AOF文件进行同步,何时同步由操作系统决定。
#define REDIS_BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
if (sdslen(server.aof_buf) == 0) return;
// 每秒进行同步
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
sync_in_progress = bioPendingJobsOfType(REDIS_BIO_AOF_FSYNC) != 0;
}
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* aof_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
latencyStartMonitor(latency);
aof_fsync(server.aof_fd); /* Let's try to get this data on the disk */
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
if (!sync_in_progress) aof_background_fsync(server.aof_fd);
server.aof_last_fsync = server.unixtime;
}
AOF文件的载入与数据还原
因为AOF文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍AOF文件里面保存的写命令,源码在redis.c/initServer方法
Redis读取AOF文件并还原数据库状态的详细步骤如下:
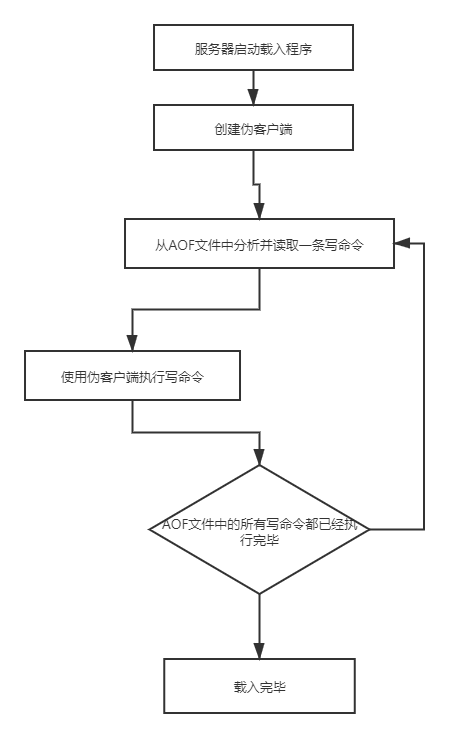
一般来说,会优先加载AOF文件:
/* Open the AOF file if needed. */
if (server.aof_state == REDIS_AOF_ON) {
#ifdef _WIN32
server.aof_fd = open(server.aof_filename,
O_WRONLY|O_APPEND|O_CREAT|_O_BINARY,_S_IREAD|_S_IWRITE);
#else
server.aof_fd = open(server.aof_filename,
O_WRONLY|O_APPEND|O_CREAT,0644);
#endif
if (server.aof_fd == -1) {
redisLog(REDIS_WARNING, "Can't open the append-only file: %s",
strerror(errno));
exit(1);
}
}
/* Function called at startup to load RDB or AOF file in memory. */
void loadDataFromDisk(void) {
PORT_LONGLONG start = ustime();
if (server.aof_state == REDIS_AOF_ON) {
//loadAppendOnlyFile为AOF加载持久化文件
if (loadAppendOnlyFile(server.aof_filename) == REDIS_OK)
redisLog(REDIS_NOTICE,"DB loaded from append only file: %.3f seconds",(float)(ustime()-start)/1000000);
} else {
if (rdbLoad(server.rdb_filename) == REDIS_OK) {
redisLog(REDIS_NOTICE,"DB loaded from disk: %.3f seconds",
(float)(ustime()-start)/1000000);
} else if (errno != ENOENT) {
redisLog(REDIS_WARNING,"Fatal error loading the DB: %s. Exiting.",strerror(errno));
exit(1);
}
}
}
int loadAppendOnlyFile(char *filename) {
struct redisClient *fakeClient;
.....
//创建一个Redis伪客户端
fakeClient = createFakeClient();
}
/* In Redis commands are always executed in the context of a client, so in
* order to load the append only file we need to create a fake client. */
struct redisClient *createFakeClient(void) {
struct redisClient *c = zmalloc(sizeof(*c));
selectDb(c,0);
c->fd = -1; //创建伪客户端,所有文件句柄为-1
c->name = NULL;
c->querybuf = sdsempty();
c->querybuf_peak = 0;
c->argc = 0;
c->argv = NULL;
c->bufpos = 0;
c->flags = 0;
c->btype = REDIS_BLOCKED_NONE;
/* We set the fake client as a slave waiting for the synchronization
* so that Redis will not try to send replies to this client. */
c->replstate = REDIS_REPL_WAIT_BGSAVE_START;
c->reply = listCreate();
c->reply_bytes = 0;
c->obuf_soft_limit_reached_time = 0;
c->watched_keys = listCreate();
c->peerid = NULL;
listSetFreeMethod(c->reply,decrRefCountVoid);
listSetDupMethod(c->reply,dupClientReplyValue);
initClientMultiState(c);
return c;
}
AOF重写,由于AOF持久化是通过保存被执行的写命令来记录数据状态的,所以AOF文件内容会越来越多,AOF重写命令是 通过对同一个key的多次操作最终保存为一个记录
代码如下:
触发aof重写时机
/* Trigger an AOF rewrite if needed */
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
redisLog(REDIS_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
具体执行逻辑,还是通过fork子进程来触发重写,具体的逻辑在aof.c/rewriteAppendOnlyFile方法中,
大概的流程为
创建新的AOF文件,然后遍历数据库,拿到所有的key,根据key得到的value判断当前的数据类型,不同的类型
执行不同的重写方法
但是这里有个问题,AOF重写的时候数据可能不是最新的,因为在子进程进行AOF重写期间,服务器进程可以继续处理命令请求
为了解决这种数据不一致问题,Redis服务器设置了一个AOF重写缓冲区,
在redisServer中定义:
list *aof_rewrite_buf_blocks; /* Hold changes during an AOF rewrite. */
sds aof_buf; /* AOF buffer, written before entering the event loop */
说明在服务器执行期间,会做三个操作:
1、执行客户端发来的命令
2、执行后的写命令追加到AOF缓冲区
3、执行后的写命令追加到AOF重写缓冲区
当子进程完成AOF重写工作之后,他会向父进程发送一个信号,父进程收到信号后,会执行AOF重写缓冲区数据,然后之后
执行文件替换,完成整个操作。代码在aof.c/backgroundRewriteDoneHandler